
Back to blog

Why Doesn’t S3 Have a Built-In CDN?

File storage is one of the core components to most applications. It is often the second or third thing developers find themselves needing to write code for. What many forget about, until they are hit with the complexity of setting it up, is that file storage is just half the equation. Retrieval of those files is every bit as important.
The Parable of Despair
You’ve run into the problem before. Your application needs file storage, so you reach for the thing everyone has been using for more than a decade. Amazon’s S3 (Simple Storage Service) has been the defacto solution for developers for nearly its entire existence. So, you fight through the poor developer experience and configure your bucket and IAM policies and hope to the developer gods that you aren’t accidentally making your files bucket available. You get file storage connected to your application and you’re about to breathe a sigh of relief when you remember something.
You need to retrieve those files too.
S3 has a way for you to retrieve files, but it’s not optimized for worldwide (or even country-wide) performance. And don’t even look at the prices. The egress (bandwidth) cost for loading your files from S3 will make your eyes water. So, it’s time to put your DevOps hat back on and figure out how to layer a CDN on top of your S3 bucket.
All you wanted to do was let your application upload files and be able to render those files in the app’s interface. What you ended up with was a bird’s nest of services with complex rules and maintenance requirements. After spending hours (or days) setting all of this up just to get your new application off the ground, you’re probably asking why S3 doesn’t have a built-in CDN. You’re also probably asking why you chose S3 in the first place.
The answer to both questions is market dominance.
S3 has built up the advantage that comes with being a first-move and the advantage that comes with being built by one of the world’s largest companies. But the advantage is almost entirely perceptual. And that’s good news. That means developers have options that they may not have been aware of.
The New (Better) Path Forward
File storage should come with a CDN by default. Simple as that. It is a rare situation where a developer is uploading files with no expectation of retrieving those files anytime soon. It’s with this concept in mind that we designed Pinata Gateways.
A Pinata Gateway, at its core, is a CDN. It lets you load files you’ve stored and it ensures speed, reliability, and global reach. You get this out of the box without having to reach for another service or set up additional configuration.
Beyond the CDN functionality, Pinata Gateways come with additional perks. Want a custom domain? No problem. A Gateway per project? Go for it. Private and public file support. Done. Plugins to extend the functionality further. You got it.
Best of all, loading files in your app is dead-simple. With a single line you can generate a signed URL and load the file.
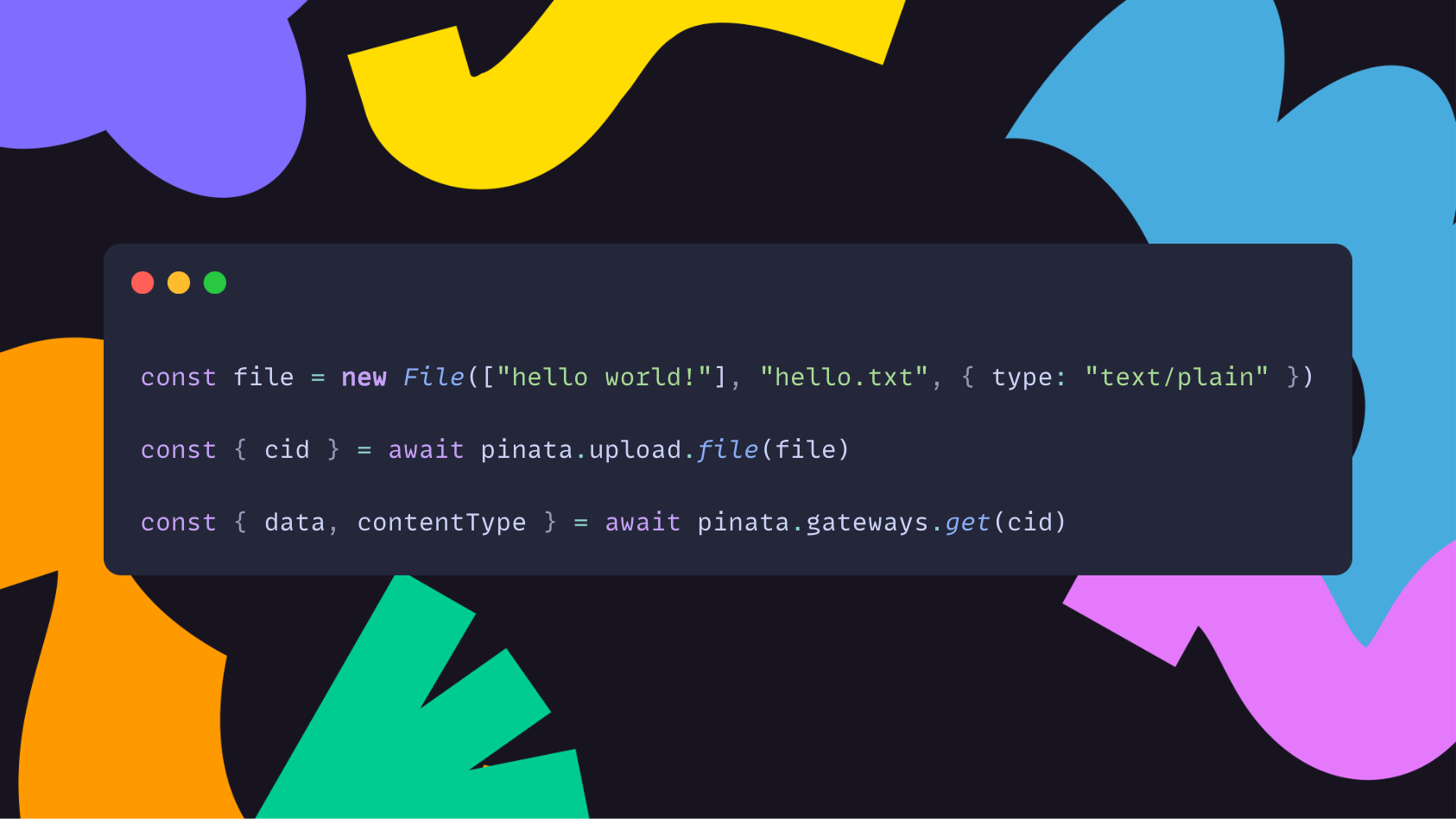
If you’d prefer more granular control over access files, you can also easily generate your own signed URL and use it however you’d like:
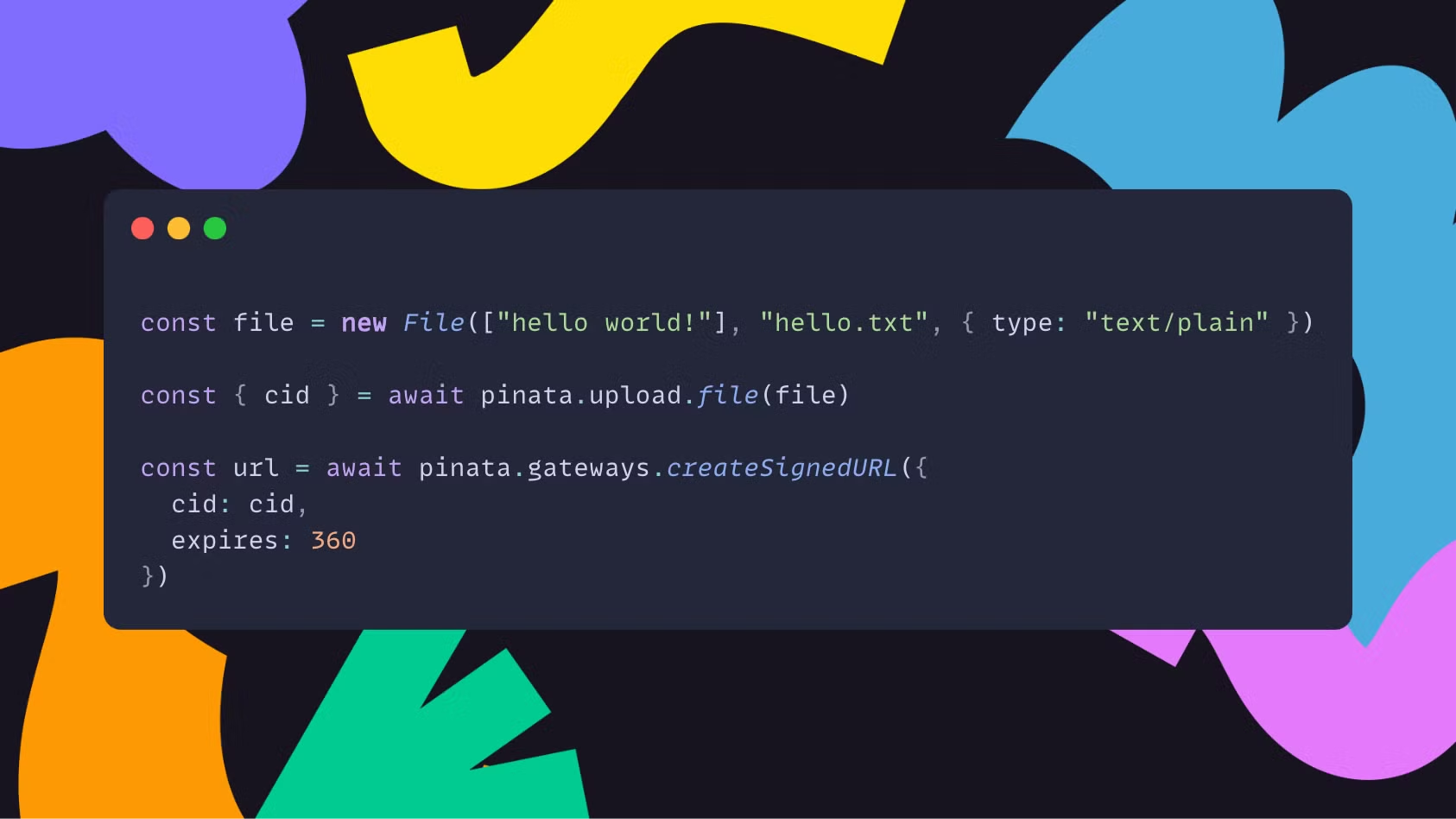
Conclusion
Not only is Pinata’s Files API easier than S3, it’s every bit as capable, but with more functionality out of the box. So, revisiting the original question: why doesn’t S3 have a built-in CDN? Because their goal isn’t simplicity. Pinata’s is.
Get started with Pinata today for free. Happy building!