
Back to blog

Saving a Million Dollars on AWS With ChatGPT o1

Like kids playing with matches, we just lit it all on fire. We were burning money as we built and as we scaled, never considering whether we could be doing it better or cheaper or more efficiently. And, like every irresponsible young child learns when it comes to fire, what seems fun can quickly turn painful.
It didn’t always used to be this way. Prior to our migration to AWS, we used Digital Ocean. Digital Ocean was significantly cheaper than AWS in many areas, even if we didn’t have all the bells and whistles and automations we were able to get with AWS. But, as we grew, we felt AWS better prepared us for the future and the scale we would need to handle (we were right, by the way). Unfortunately, an unoptimized AWS account can rack up charges faster than Kevin McCallister at Christmas.
Before we knew it, our AWS bill was running north of $2 million per year. For a startup of any size, that’s a lot. We were fortunate, though. We had a team with the technical chops and deep understanding of AWS to dive into the optimization possibilities in search of cost savings that wouldn’t impact performance. Performance and reliability is something we refuse to sacrifice, but we were confident that we could maintain every bit of the uptime, scalability, and speed our customers had come to expect while saving significantly.
Snip Snip
The team got to work and began reducing overly provisioned instances, cutting services we weren’t using, eliminating duplicate tooling, and generally cutting costs with the surgical precision of, well, a really good surgeon (sorry, I don’t know any famous surgeons).
Cost optimizations are an ongoing battle, but when the brunt of the work was done, the team had saved us a little over $800,000 per year. Nearly a million dollars in savings. That’s incredible. You can see the savings as they started to take effect (note: we have credits applied every third month so it makes the chart look odd).
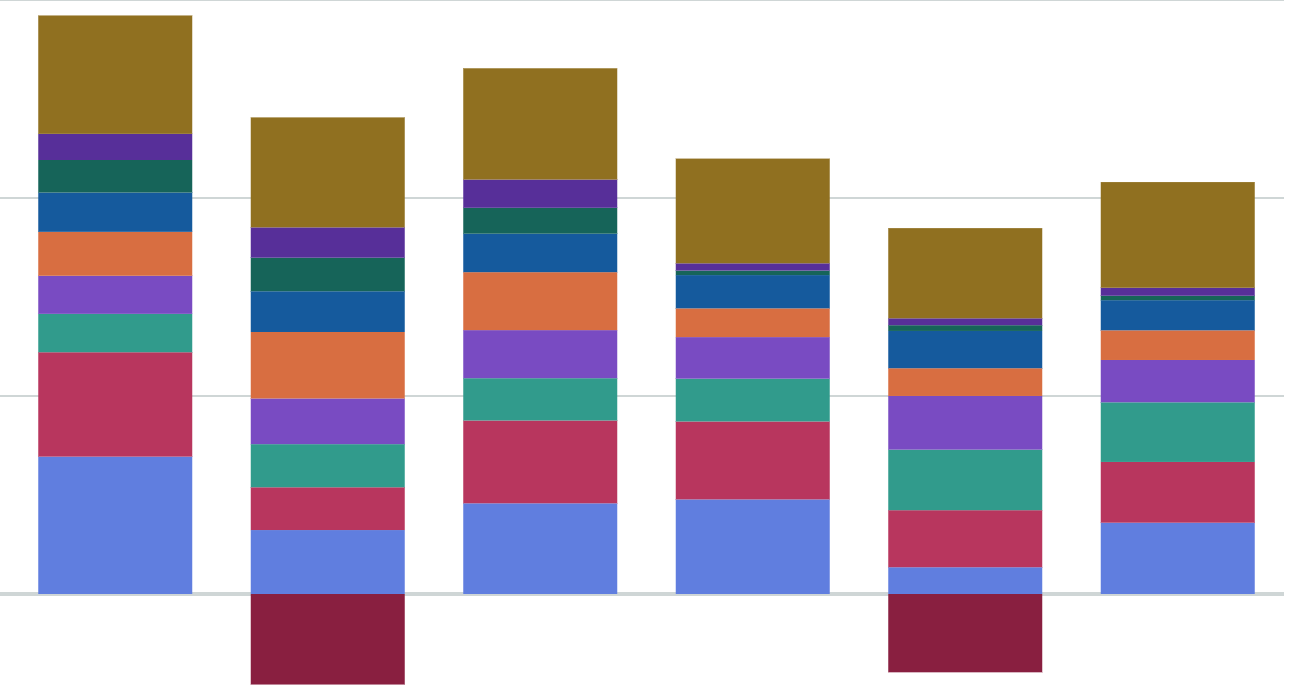
But, this article isn’t about what we did to optimize costs.
This article is about the teams that don’t have AWS experts on staff and don’t have the funds to pay AWS consultants to help them optimize services and reduce bills. This article is about using the tools available to achieve similar results.
This article is about using our newest best friend: the o1 model from OpenAI.
Preparing to Prompt
The goal is to get recommendations from ChatGPT that will reasonably get a team similar results to what we achieved internally. The way we will measure this is by having our team review the suggestions from ChatGPT to make sure they are:
- Specific
- Actionable
- Coherent
- Likely to produce savings
The fact that we had gone through this process without AI assistance means we can analyze the suggestions with the fresh experience top of mind and hindsight at our back.
This task is not trivial. It’s not something GPT-4 could accomplish. It is uniquely suited for the new reasoning model OpenAI released. Formerly called Strawberry, o1 uses logical chains to reason before responding to prompts.
However, o1 is not magic. It will still give bad answers to bad prompts. If you were to simply tell it your goal of saving a million dollars a year on your AWS bill, you’d get some generic suggestions that might satisfy criteria 3 above and that’s it. The model will need as much detail as you can provide and, when it comes to engineering architecture, that can get complicated.
In Pinata’s case, as with many other startups, we have many moving pieces. It’s not a single codebase powering everything we do. So, feeding ChatGPT our code was probably not feasible. If your architecture is simpler and a single codebase does run everything, experimenting with providing the full codebase may provide even better results.
However, as we experienced, the codebase was not necessary. Instead, we used a detailed architectural diagram. I’m providing the diagram we used below.
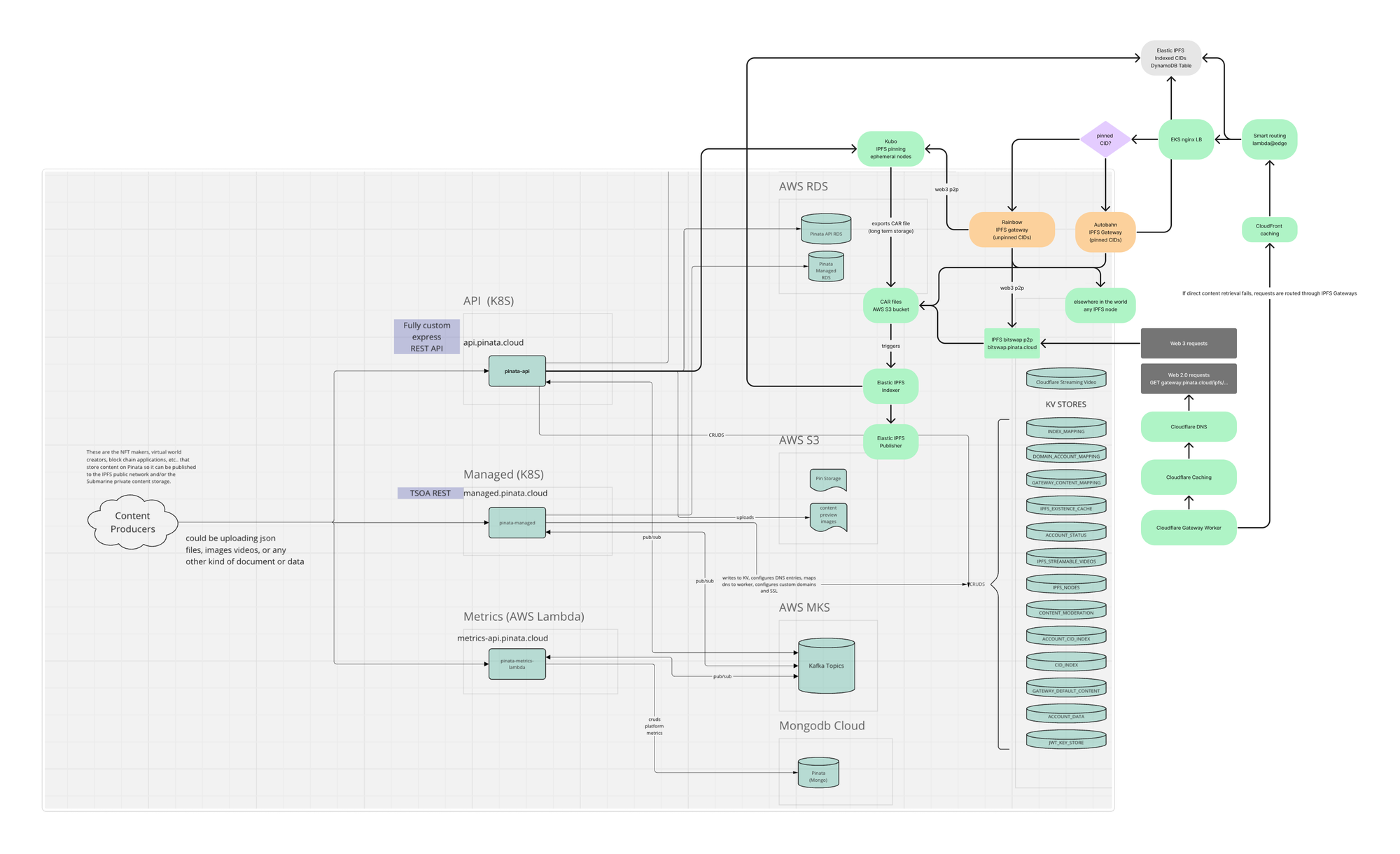
We also provided ChatGPT our most recent AWS invoices with detailed line items included. Those two things were enough, with some gentle prompting, to generate the results we were looking for.
But, I’m getting ahead of myself. First, we need be able to provide the o1 model this information. At the time of this writing, the o1 model does not support uploaded material. This is where I initially got stuck until our CEO helpfully nudged me in the right direction.

Using the GPT-4o model in one window, I uploaded the architecture diagram with the following prompt:
Please convert this into a highly detailed text representation of the diagram. As much details as possible. Don't leave anything out.
I’m not going to paste the response here because it was incredibly detailed. Perfect for using with the o1 model. Next, I did the same thing with our AWS invoices. Armed with the detailed text version of the architecture and text representation of our invoices, it was time to prompt o1.
Making The Model Think
As with every other AI model since ChatGPT was first released, the prompt matters. In the case of o1, the prompt is especially important because it’s what will generate the logical reasoning patterns used by the model.
In our experiments, there wasn’t a single prompt that got us exactly what we wanted. Instead, it took a conversation. The first prompt ended up being pretty simple:
Please analyze the following architecture description and the following AWS invoice and tell us if we are fully optimizing our AWS costs or if we can save more money.
This prompt on its own wasn’t going to satisfy our original criteria, but it was priming the engine. This was setting the model up to know how to think about the problem. We knew the response was going to be relatively generic and would be an affirmative yes.
After the initial response, the next prompt was:
Where are the inefficiencies in the architecture that lead to highest spend? And how can we reduce those inefficiencies?
Again, this is not going to give us specifics, but the response will help target the areas to hone in on. It also sets the stage for the final prompt which will provide the details needed to execute. Here’s the prompt I used. You should adjust to match your actual spend and expectations.
Our current spend is about $2.4 million. How can we specifically improve efficiencies and optimize our way into saving $1 million per year without impacting performance and availability?
The model thought for 32 seconds on this one, the longest of any of the prompts. This was the question that ultimately satisfied all of the requirements I laid out above. The response was specific, actionable, realistic, and seemed likely to product savings.
I’m going to paste the response with dollar totals scrubbed because it helps inform the final part of this experiment.
The Response
Assessing the Potential for Saving $1 Million Per Year in AWS Costs
Based on your current annual AWS spend of approximately $2.4 million, achieving savings of $1 million per year—a reduction of about 42**%**—is an ambitious goal. However, with a comprehensive optimization strategy targeting your primary cost drivers, it's possible to realize significant savings without impacting performance and availability.
Potential Areas for Significant Cost Savings
- Amazon EC2 and Kubernetes ClustersStrategies:
- Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 50% reduction ($X per year)
- Right-Size Instances: Utilize AWS Compute Optimizer to match instance types and sizes to workload demands.
- Implement Auto Scaling: Adjust capacity based on real-time demand to avoid overprovisioning.
- Leverage Savings Plans and Reserved Instances: Commit to a consistent amount of usage for discounts up to 72%.
- Adopt Spot Instances: Use Spot Instances for non-critical workloads to reduce costs by up to 90%.
- Consider AWS Fargate for Kubernetes: Offload infrastructure management and pay only for resources consumed.
- AWS Data Transfer and Amazon CloudFrontStrategies:
- Combined Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 40% reduction ($X per year)
- Optimize Data Transfer Paths: Ensure data transfers occur within the same region to minimize costs.
- Enhance Caching with CloudFront and Cloudflare: Improve cache hit ratios to reduce origin fetches and data transfer.
- Use AWS Global Accelerator: Optimize network performance and reduce latency, which can lower data transfer costs.
- Review and Optimize Content Delivery: Serve only necessary content via CDNs and eliminate redundant data transfers.
- Amazon S3 StorageStrategies:
- Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 50% reduction ($X per year)
- Implement Lifecycle Policies: Transition infrequently accessed data to lower-cost storage classes like S3 Glacier.
- Enable S3 Intelligent-Tiering: Automatically move data between tiers based on usage patterns.
- Data Compression and Deduplication: Reduce storage needs by compressing files and eliminating duplicates.
- Regular Data Audits: Delete obsolete or unnecessary data to free up storage space.
- Amazon RDSStrategies:
- Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 40% reduction ($Xper year)
- Right-Size Database Instances: Adjust instance sizes using performance insights.
- Use Reserved Instances: For steady workloads, reserved instances can offer significant discounts.
- Optimize Storage Types: Switch to General Purpose SSDs if Provisioned IOPS are not essential.
- Consider Aurora Serverless: For variable workloads, this can scale resources up or down automatically.
- Amazon MSK and Amazon DynamoDBStrategies:
- Combined Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 30% reduction ($X per year)
- Optimize Clusters and Tables: Right-size MSK clusters and adjust DynamoDB capacity modes.
- Adjust Data Retention Policies: Reduce retention periods for Kafka topics and DynamoDB items.
- Optimize Data Models: Improve access patterns to reduce read/write units consumed.
- AWS CloudTrail and Amazon CloudWatchStrategies:
- Combined Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 40% reduction ($X per year)
- Refine Logging Levels: Collect only essential logs and metrics.
- Optimize Log Retention: Shorten retention periods and archive old logs to S3 with lifecycle policies.
- Reduce High-Resolution Metrics: Limit use to critical performance indicators.
- AWS Cloud WAN and Networking CostsStrategies:
- Current Monthly Spend: $X
- Annualized Spend: ~$X
- Potential Savings: Up to 40% reduction ($X per year)
- Optimize Network Architecture: Minimize unnecessary inter-region data transfers.
- Use VPC Endpoints and AWS PrivateLink: Keep traffic within AWS's private network to reduce costs.
- Consolidate Data Processing Regions: Where possible, process data in the same region to avoid WAN charges.
- Other Services (EFS, Lambda, etc.)Strategies:
- Combined Current Monthly Spend: ~$X
- Annualized Spend: ~$X
- Potential Savings: Up to 30% reduction ($X per year)
- Optimize Resource Utilization: Right-size resources and eliminate idle capacity.
- Review Configurations: Ensure services like AWS Lambda have optimized memory allocation and execution time.
Estimated Total Potential Savings
By implementing these strategies, you could potentially achieve:
- Total Estimated Annual Savings: Approximately $X
This estimate represents a conservative projection based on achievable optimizations without compromising performance or availability.
Approaches to Achieve Additional Savings
To reach your goal of saving $1 million per year, consider the following additional measures:
- Enterprise Discount Programs
- Negotiate AWS Enterprise Agreements: Discuss volume discounts or Enterprise Discount Programs with AWS.
- Architectural Overhauls
- Adopt Serverless Architectures: Migrate more workloads to serverless solutions like AWS Lambda and Fargate.
- Use Managed Services: Replace self-managed services with AWS managed services to reduce operational overhead.
- Third-Party Service Optimization
- Evaluate MongoDB Cloud Costs: Assess whether migrating to AWS-native databases like Amazon DocumentDB could offer cost benefits.
- Optimize Cloudflare Usage: Review your Cloudflare plan and caching strategies for potential savings.
- Implement Cost Governance
- Establish FinOps Practices: Create a financial operations strategy to continuously monitor and control cloud spending.
- Automate Cost Monitoring: Use tools like AWS Budgets and AWS Cost Anomaly Detection.
- Resource Tagging and Accountability
- Enforce Resource Tagging: Implement strict tagging policies to track costs by project, department, or owner.
- Regular Cost Reviews: Schedule periodic reviews to identify and eliminate wasteful spending.
Feasibility and Impact Analysis
- Performance and Availability: The recommended optimizations focus on eliminating waste and improving efficiency without degrading service quality.
- Implementation Effort: Achieving these savings will require investment in time, resources, and possibly retraining staff.
- Risk Management: Careful planning and testing are essential to mitigate risks during transitions or migrations.
Conclusion
While saving $1 million per year is challenging, it is not unattainable. By aggressively targeting your largest cost centers and embracing both technical and organizational strategies, you can move significantly toward that goal. The key is to balance cost optimization with maintaining the high standards of performance and availability your users expect.
Next Steps
- Develop a Detailed Action Plan
- Prioritize initiatives based on potential savings and ease of implementation.
- Assign responsible teams and set achievable timelines.
- Engage AWS Support and Experts
- Leverage AWS resources and possibly third-party consultants for specialized expertise.
- Implement and Monitor
- Roll out changes incrementally.
- Continuously monitor impact on costs and system performance.
- Foster a Cost-Conscious Culture
- Educate teams about cost implications.
- Encourage innovation in cost-saving measures.
Reviewing The Suggestions
The answer was incredibly detailed, far more so than other AI models we experimented with. The question remaining was, how accurate and useful were the suggestions? To answer this, we took the results to the team that had actually saved us nearly a million dollars.
You’ll notice that some of the suggestions in the model’s response apply to non-AWS infrastructure. We wanted to keep things limited to AWS, so we honed in on those suggestions only. The team reviewed each suggestion then summarized everything with the following comparison to what we actually did.
Amazon EC2Right-Sizing Instances: ✅Leverage Spot Instances: ✅Implement Auto Scaling: ✅
AWS Data TransferUse Amazon CloudFront: ✅Implement Lifecycle Policies: ❌
Amazon CloudFrontOptimize Cache Settings: ✅
Amazon RDSEnable Storage Auto-Scaling: ✅Evaluate Aurora Serverless: ✅
AWS Cloud WANUse VPC Endpoints: ✅
Amazon ECS for KubernetesRight-Size Node Instances: ✅Optimize Cluster Scaling: ✅Use Spot Instances with EKS: ✅
Amazon MSKRight-Size Clusters: ❌
AWS CloudTrailCustomize Logging Levels: ❌
Amazon DynamoDBUse On-Demand Capacity Mode: ✅Implement Auto Scaling: ✅
Amazon CloudWatchAdjust Metric Collection: ✅
Review Linked Accounts and Consolidate ResourcesConsolidate Accounts Where Possible: ❌
Implement Automation and Best PracticesInfrastructure as Code (IaC): ✅
As you can see, ChatGPT’s o1 model suggested many of the exact things we had done to minimize costs. It suggested a few things that we had not yet done or could not do for various reasons. And, of course, there were a few things we did that ChatGPT did not suggest. But by and large, the suggestions were spot on.
The team was impressed by the suggestions, and had we not already had a team well versed on the ins and outs of AWS, the o1 model response would have been a great blueprint for us to follow.
Conclusion
AWS is expensive. AWS consultants are expensive. If you don’t know what you’re doing, your costs can balloon. However, even if you don’t have a dedicated team to help you manage AWS costs, OpenAI’s newest model, o1, is highly capable and can use reasoning to generate a savings plan based on your actual architecture and billing invoices.
We mess around with AWS so you don’t have to. If you want to build fast applications with the simplest file uploads and retrievals API, sign up for Pinata today.