
Back to blog

How To Build Search For Your NFT Collection

Many NFT collections launch and then rely on NFT marketplaces to do their, well, marketing. If someone wants to see all of the possible NFTs in the collection, they often have to go to a marketplace and filter with whatever tools the marketplace provides. What if these people could come to the NFT project creator’s homepage and search, using natural language, for NFTs in the collection?
Today, we’re going to build exactly that. We’re going to use the Pudgy Penguin NFT collection as an example because they remain popular today, and their NFT metadata and images are already stored on IPFS via Pinata. We’ll create a simple interface with a search box. We’ll use Pinata’s Vector Storage to store vectorized versions of the collection, and we’ll use the vector search functionality to find similar matches to the user’s natural language search.
Ready to dive in?
Getting Started
An NFT collection generally contains more files than you can store on the Pinata Free Plan, and this tutorial is no different. So, while I am going to vectorize the entire collection of 8,888 Pudgy Penguins, you can set your script to stop at 500 and stay within the free plan limits (I’ll show you how).
So, first thing you’ll need to do is sign up for a free Pinata account here. Then, we’ll want to do a few things while we’re in the web app:
- Go to the API Keys page and generate a new admin API key. Save the resulting JWT somewhere safe as we’ll need it soon.
- Navigate to the Gateways page and copy the gateway URL. We’ll need that soon as well.
- Go to the Groups tab in the Storage section and create a new group. Call it whatever you’d like. Then click on the new group, and in the URL bar, you’ll see the Group ID. Copy that and save it somewhere until we need it.
- Finally, go to the Access Controls tab on the left under the IPFS section. Create a new gateway key for your gateway, and save it.
Other than that, you’ll need a code editor and Node.js installed on your machine.
Let’s go ahead and get our project ready by firing up the terminal app you use, navigating to the directory where you keep your projects, and running this command:
npx create-next-app nft-search
Respond to the prompts however you’d like, but I will be using Next.js’s app router and Tailwind. Once that’s done, change into the project directory like so:
cd nft-search
And we’re ready to start building!
Vectorizing an NFT collection
We’re going create a one-time script to fetch and vectorize the NFT metadata from the Pudgy Penguin collection. You can find the collection’s smart contract details on Etherscan here. If you click the baseTokenURI function, you’ll the result is:
ipfs://bafybeibc5sgo2plmjkq2tzmhrn54bk3crhnc23zd2msg4ea7a4pxrkgfna/ string
That IPFS content identifier (CID) represents the directory in which all the Pudgy Penguin NFT metadata is hosted. We know based on the contract’s totalSupply function that there are 8,888 NFTs in the collection. I have also already done the work of checking to see if the NFTs start at 0 or at 1. They start at 0, which we will need to know very soon.
In our project directory, let’s create a folder at the root of the directory called scripts. Inside that folder, add a file called find_and_vectorize.js. Inside that file, add the following:
const { PinataSDK } = require("pinata");
require("dotenv").config();
const pinata = new PinataSDK({
pinataJwt: process.env.PINATA_JWT,
pinataGateway: process.env.PINATA_GATEWAY_URL,
});
const createTokenArray = () => {
try {
let count = 0;
let tokens = [];
const maxTokens = 8888
while (count < maxTokens) {
tokens.push(count);
count++;
}
return tokens;
} catch (error) {
console.error("Error creating token array:", error);
throw error;
}
};
const processFile = async (id) => {
try {
await pinata.upload
.url(`https://${process.env.PINATA_GATEWAY_URL}/ipfs/${process.env.CID}/${id}?pinataGatewayToken=${process.env.GATEWAY_KEY`)
.group(process.env.GROUP_ID)
.vectorize();
console.log("Vectorized token id: ", id);
} catch (error) {
console.error(`Error processing token ${id}:`, error);
process.exit(1);
}
};
(async () => {
try {
const pLimit = await import("p-limit").then((mod) => mod.default);
const tokenIds = createTokenArray();
const limit = pLimit(20); // Limit the concurrency to 3
const fileProcessingPromises = tokenIds.map((id) =>
limit(() => processFile(id))
);
await Promise.all(fileProcessingPromises); // Wait for all promises to resolve
console.log("All files processed successfully.");
} catch (error) {
console.error("Error in main process:", error);
process.exit(1);
}
})();
This code will use your uses the Pinata SDK’s built-in upload from URL method to upload and vectorize each NFT metadata file from the Pudgy Penguins collection. We use our gateway to build the full URL for the metadata, and we need the gateway key because the content is not stored on our Pinata account.
If you’re on the free plan and want to just test with 500 or fewer of these files, adjust the maxTokens variable. Additionally, if you find when you run this script that you run into problems, you can adjust the concurrency number in the pLimit(20) function. Change that to something lower if you need to.
Before running the script, we’re going to need to install some dependencies and get our environment variables set up, then we’ll talk through this file. Let’s install dependencies first:
npm i pinata p-limit dotenv
We’re installing the Pinata Files SDK, p-limit a concurrency limiter for using promise.All in scripts, and dotenv which allows us to read out environment variable file in our script.
Now, let’s create a .env file at the root of our project. In that file, add the following:
PINATA_JWT=YOUR PINATA JWT
PINATA_GATEWAY_URL=YOUR PINATA GATEWAY URL
GROUP_ID=YOUR GROUP ID
CID=bafybeibc5sgo2plmjkq2tzmhrn54bk3crhnc23zd2msg4ea7a4pxrkgfna
GATEWAY_KEY=YOUR PINATA GATEWAY KEY
All those things we did in the Pinata web app at the beginning of the tutorial, we’re going to use them here. Fill in the .env file with the actual values from your Pinata account.
Now, it’s time to run our script. In your terminal, run the following:
node scripts/find_and_vectorize.js
You’ll see the progress as the script runs. For me, it took fewer than 5 minutes to upload and vectorize all 8,888 metadata files. Once the script finishes, it’s time to actually build our app!
Building the app
I always like to start with my API routes when building an app. For this, we will need just two routes. Let’s create a folder in the app directory called api. Inside that, create another folder called search. And then, create a file in the search directory called route.ts.
We’ll do the same for the other route. Inside the api folder, add another folder called image and inside the image folder, add a file called route.ts.
The search route will be used to handle the user’s search queries and return results. The image route will be used to proxy requests for the NFT images using our gateway. The reason we want to proxy these through the backend is because we don’t want to expose our Gateway Key to the frontend. If we did that, any malicious actor could use our gateway to fetch any content they want from the entire IPFS network.
We’ll start with the search endpoint. In the search/route.ts file, add the following:
import { pinata } from "@/app/pinata";
import { NextRequest, NextResponse } from "next/server";
export async function POST(req: NextRequest, res: NextResponse) {
try {
const { query } = await req.json();
const results = await pinata.files.queryVectors({
groupId: process.env.GROUP_ID!,
query: query,
});
const { matches } = results;
const data = []
for(const match of matches) {
const file = await pinata.gateways.get(match.cid);
data.push(file.data)
}
return NextResponse.json({ data })
} catch (error) {
console.log(error);
return NextResponse.json({ "server error": error }, { status: 500 });
}
}
This endpoint takes the user’s search query from the request body, then it uses the Pinata SDK and Pinata’s Vector Search functionality to find the best results based on that query. Because the results are individual metadata files, we’re going to also make requests with the SDK to get the raw metadata for the NFTs and build our response object.
Now, let’s work on the image route. In the image/route.ts file, add the following:
import { NextRequest, NextResponse } from "next/server";
export async function POST(req: NextRequest, res: NextResponse) {
try {
const { cid } = await req.json()
const stream = await fetch(`${process.env.NEXT_PUBLIC_GATEWAY_URL}/ipfs/${cid}?pinataGatewayToken=${process.env.GATEWAY_KEY}`)
const buffer: any = await stream.arrayBuffer()
return new NextResponse(buffer);
} catch (error) {
console.log(error);
return NextResponse.json({ "server error": error });
}
}
Before we build the user interface, let’s test this out. Run the app by entering the following in your terminal:
npm run dev
Then, in another terminal window, enter this curl command:
curl --location '<http://localhost:3000/api/chat>' \\
--header 'Content-Type: application/json' \\
--data '{
"messages": [
{
"role": "user",
"content": "How can I upload a file to a group?"
}
]
}'
You should see a result with matching NFTs that have the afro pick attribute. That’s exactly what we want! Now, we can build our interface.
In the app/pages.tsx file, let’s update the entire thing to look like this:
"use client";
import { useState } from "react";
type Attribute = {
trait_type: string;
value: string;
};
type Pudgy = {
attributes: Attribute[];
description: string;
image: string;
name: string;
rawImage?: string;
};
export default function Home() {
const [query, setQuery] = useState("");
const [results, setResults] = useState<Pudgy[]>([]);
const [isLoading, setIsLoading] = useState(false);
const fetchImages = async (resultData: Pudgy[]) => {
for (const result of resultData) {
const data = JSON.stringify({
cid: result.image.split("//")[1],
});
const res = await fetch(`/api/image`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: data,
});
const blob = await res.blob();
const objectUrl = URL.createObjectURL(blob);
result.rawImage = objectUrl;
setResults((prevResults) =>
prevResults.map((item) =>
item.name === result.name ? { ...item, rawImage: objectUrl } : item
)
);
}
};
const search = async () => {
setIsLoading(true);
setResults([]);
const res = await fetch("/api/search", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ query }),
});
const data = await res.json();
setResults(data.data);
await fetchImages(data.data);
setIsLoading(false);
};
const LoadingIcon = () => (
<svg
xmlns="<http://www.w3.org/2000/svg>"
xmlnsXlink="<http://www.w3.org/1999/xlink>"
style={{
margin: "auto",
background: "none",
display: "block",
shapeRendering: "auto",
}}
width="50px"
height="50px"
viewBox="0 0 100 100"
preserveAspectRatio="xMidYMid"
>
<circle
cx="50"
cy="50"
r="32"
strokeWidth="8"
stroke="#4A90E2"
strokeDasharray="50.26548245743669 50.26548245743669"
fill="none"
strokeLinecap="round"
>
<animateTransform
attributeName="transform"
type="rotate"
repeatCount="indefinite"
dur="1s"
keyTimes="0;1"
values="0 50 50;360 50 50"
></animateTransform>
</circle>
</svg>
);
return (
<div className="min-h-screen bg-white flex flex-col items-center">
<div
className={`w-full max-w-[1200px] px-4 transition-all duration-300 ${
results.length > 0 ? "mt-4" : "flex-1 flex items-center justify-center"
}`}
>
<div className="w-full max-w-[800px]">
<div className="flex items-center space-x-2 mb-4">
<input
className="px-4 py-2 bg-gray-100 border border-gray-300 rounded-md flex-1"
placeholder="Search the Pudgy Penguins"
type="text"
value={query}
onChange={(e) => setQuery(e.target.value)}
/>
<button
onClick={search}
className="px-4 py-2 bg-blue-500 text-white rounded-md hover:bg-blue-600"
disabled={isLoading}
>
{isLoading ? "Loading..." : "Search"}
</button>
</div>
</div>
</div>
{isLoading && !results.length && (
<div className="flex justify-center items-center">
<LoadingIcon />
</div>
)}
<div
className={`grid grid-cols-1 md:grid-cols-2 lg:grid-cols-4 gap-4 w-full max-w-[1200px] px-4 ${
results.length > 0 ? "mt-8" : ""
}`}
>
{results.map((r: Pudgy) => (
<div
key={r.name}
className="max-w-sm rounded overflow-hidden shadow-lg bg-white"
>
{r.rawImage ? (
<img className="w-full" src={r.rawImage} alt={r.name} />
) : (
<div className="w-full h-40 flex justify-center items-center">
<LoadingIcon />
</div>
)}
<div className="px-6 py-4">
<div className="font-bold text-xl mb-2">{r.name}</div>
<p className="text-gray-700 text-base">{r.description}</p>
</div>
<div className="px-6 pt-4 pb-2">
{r.attributes.map((a: Attribute) => (
<span
key={a.trait_type}
className="inline-block bg-gray-200 rounded-full px-3 py-1 text-sm font-semibold text-gray-700 mr-2 mb-2"
>
{a.trait_type} - {a.value}
</span>
))}
</div>
</div>
))}
</div>
</div>
);
}
In this component, we have created a search input. This input accepts natural language queries that we send to our backend. The result of the query is then fed into the results state variable and we start fetching the images from our backend. As the images are fetched, there’s a loading placeholder that gets replaced with the eventual image.
We have some nice UI elements in there including the loading states. But outside of that, this is a pretty straightforward search interface. Let’s see it in action.
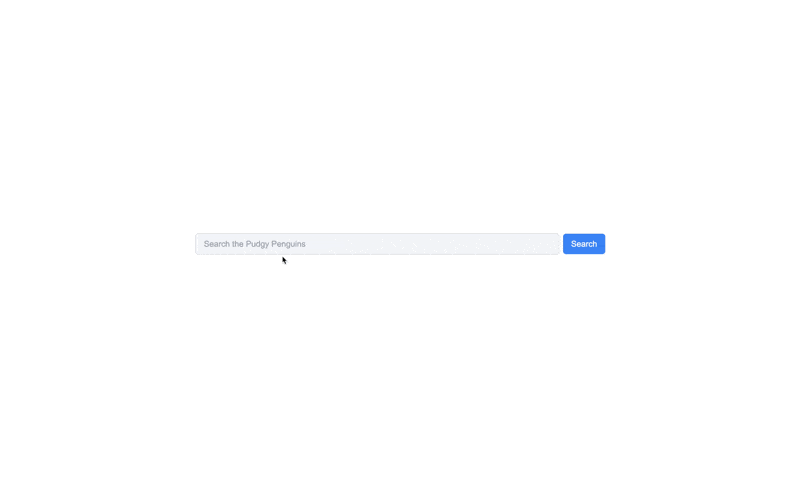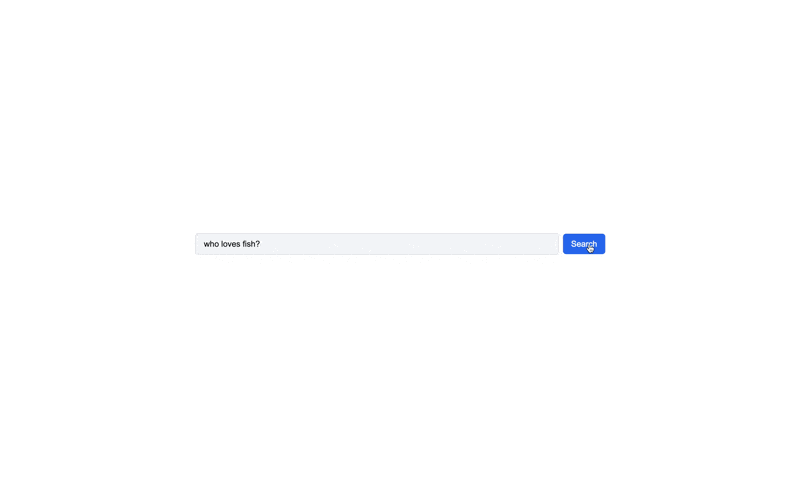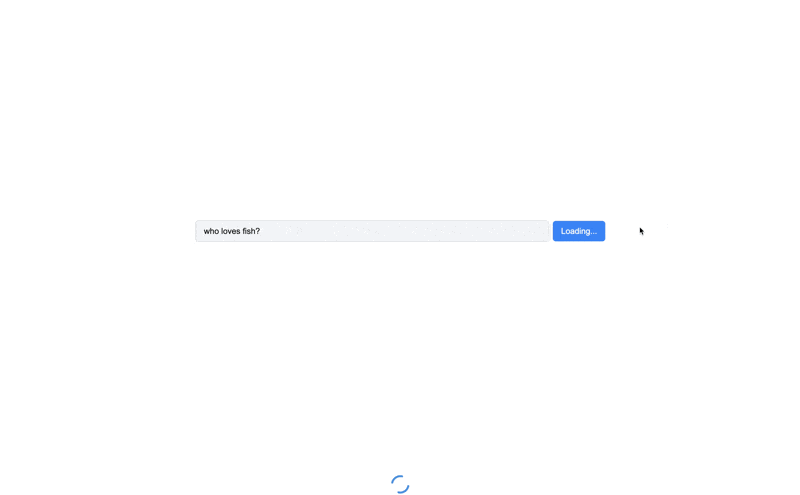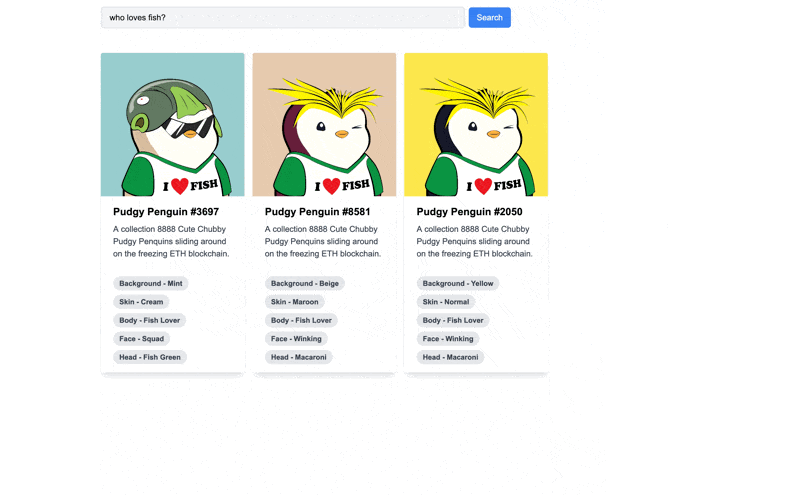
While we’re in public beta with the Pinata Vector Storage product, the maximum limit for matching results is 20. In my demo, I had the limit set to 3. However, you can see the power of using vector storage of NFT metadata combined with natural language search queries.
Conclusion
Using Pinata’s Vector Storage, combined with Pinata’s IPFS Dedicated Gateways, we were able to fetch the metadata for an entire NFT collection, vectorize it, and create a natural language search tool for the entire collection.
There are countless other directions you can take a project like this, but this quick tutorial shows the power of IPFS and vector storage and retrieval. If you’re ready to dive in, sign up for an account today.