
Back to blog

How IPFS is Changing the Game for Data Storage and Access

For anyone building and scaling applications, managing data efficiently is a top priority. Traditionally, this means relying on centralized cloud services like AWS or Google Cloud to store, distribute, and serve content. While effective, this model comes with challenges—scalability costs, single points of failure, and reliance on a few major players controlling the flow of information.
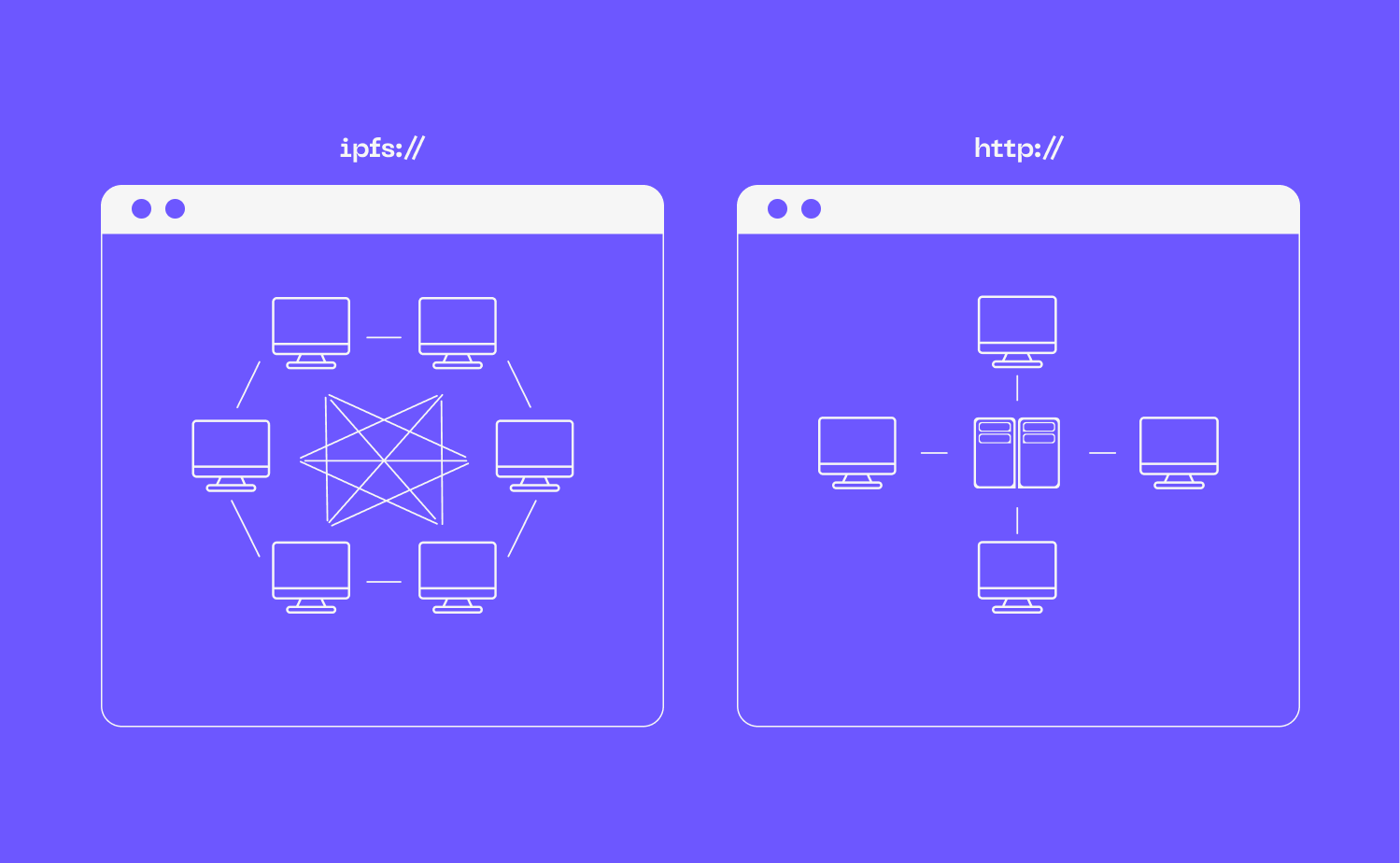
IPFS, or the InterPlanetary File System, offers a different approach. It is a peer-to-peer (P2P) protocol designed to create a distributed and decentralized web. Instead of fetching data from a single, central server, IPFS allows content to be retrieved from multiple sources at once, making storage more efficient, cost-effective, and resilient.
What problems does IPFS solve?
The internet as we know it today operates largely on HTTP (Hypertext Transfer Protocol), which is the foundation of how information is accessed and shared online. HTTP works as a request-response system where a client (such as a web browser) requests content from a specific location, usually a centralized server, and that server delivers the content back to the client. This location-based addressing means that if a server goes offline or data is removed, that content is no longer accessible. It also means that ownership and distribution of information are controlled by the entities that own the servers, creating bottlenecks, censorship risks, and vulnerabilities.
IPFS was created to solve several key issues associated with HTTP and centralized data storage:
- Centralized Control and Censorship: Since traditional HTTP-based storage relies on a single server or a cloud provider's infrastructure, access to data is ultimately controlled by those entities. If a company or government decides to block or restrict content, that data can become unavailable.
- Single Points of Failure: When content is stored on a single server, any downtime, cyberattack, or data loss can result in the loss of access to that data. Redundancy in cloud storage often comes with additional costs, but without it, there is a high risk of losing important information.
- Scalability and Cost: Delivering large files such as videos, AI training datasets, or medical images over HTTP is costly because every request requires a new connection to the centralized server. As demand grows, bandwidth costs increase, and the load on the server can cause slowdowns or failures.
- Data Availability and Integrity: HTTP relies on location-based addressing, meaning URLs point to specific locations rather than the content itself. If a file moves or is deleted, the link becomes broken, leading to lost data or missing resources. With IPFS, content is addressed by what it is rather than where it is stored, reducing the risk of broken links and making data easier to verify and retrieve over time.
These problems have real-world implications across various industries:
- Healthcare Data and Patient Records: Hospitals and research institutions handle highly sensitive patient data that requires strict access controls and compliance with privacy regulations. Private IPFS networks ensure that this data remains securely stored and accessible only to authorized parties, offering a controlled environment for sharing medical records without exposure to public networks or reliance on a single cloud provider.
- AI Model Storage (e.g., Self-Driving Cars): AI models require vast amounts of training data to function effectively. With HTTP-based storage, retrieving and updating these datasets is slow and expensive. Decentralized storage with IPFS ensures that data remains accessible and verifiable without being dependent on a single cloud provider.
- Censorship and Information Access: Governments and corporations have the power to remove or restrict access to websites and content hosted on centralized servers. With IPFS, data remains available as long as at least one node is storing it, preventing censorship and ensuring free access to information.
By decentralizing data storage and retrieval, IPFS provides a more resilient, cost-effective, and censorship-resistant alternative to traditional web infrastructure.
How IPFS Works
Unlike traditional cloud storage, where files are stored in specific data centers and retrieved by location, IPFS stores files using a content-addressed model. Here’s how it works:
- Content Addressing: Instead of assigning files a location-based URL (e.g., an S3 bucket or CDN endpoint), IPFS assigns each file a unique cryptographic hash based on its content. This ensures that files are verifiable and immutable.
- Decentralized Distribution: When a file is added to IPFS (a process called "pinning"), it is broken into smaller blocks and distributed across multiple nodes in the network. When someone requests the file, it can be retrieved from the closest or most efficient node, reducing latency and server load.
- Public vs. Private Gateways: Unlike traditional cloud storage, where access is managed via permissions within a provider’s ecosystem, IPFS allows users to control whether their data is publicly accessible or restricted through private gateways. Public gateways allow anyone to access content using the corresponding Content ID (CID), making them ideal for open datasets, decentralized applications, and publicly shared research. Private gateways, on the other hand, give complete control over who can access the content, ensuring sensitive data like patient records or proprietary AI models remain secure.
How Does This Compare to Traditional Cloud Services?
For those accustomed to cloud storage solutions, the best way to think about IPFS is as a highly efficient, decentralized content distribution network (CDN) combined with resilient, distributed storage. Here’s how it compares:
- Scalability: In a cloud-based model, scaling requires provisioning additional resources, balancing loads, and optimizing delivery through CDNs. With IPFS, scaling is organic—popular files become more widely distributed across nodes, making them easier to access without requiring more infrastructure from a single provider.
- Cost Reduction: Traditional cloud platforms charge for data egress, meaning the more your users access data, the more you pay. With IPFS, data retrieval is more efficient since users fetch content from the nearest available node, reducing bandwidth costs.
- Resilience and Redundancy: AWS and Google Cloud offer redundancy through multi-region replication, but this comes at an additional cost. IPFS inherently provides redundancy by distributing data across multiple nodes, ensuring availability even if some nodes go offline.
- Data Persistence: With cloud storage, files are accessible as long as they’re maintained by the provider. If a file is removed or a service is discontinued, access is lost. IPFS files remain available as long as at least one node is pinning them, allowing content to be preserved without relying on a central authority.
How Pinata Enhances IPFS for Businesses and Developers
Pinata was built to make IPFS more accessible and efficient for developers and enterprises. Key features include:
- Dedicated IPFS Gateways: These function like private lanes for retrieving IPFS content quickly and reliably, reducing reliance on public networks while giving total control over access permissions.
- Global CDN Integration: Pinata optimizes IPFS retrieval speeds with a built-in CDN and over 200 global server locations.
- Simplified Pinning and Management: With an intuitive interface and robust API, Pinata makes it easy to pin and manage files on IPFS without requiring deep technical expertise.
The Future of IPFS and Decentralized Infrastructure
As data storage and distribution needs evolve, decentralized protocols like IPFS present a viable alternative to traditional cloud-based models. By reducing dependency on central authorities, improving content availability, and lowering infrastructure costs, IPFS offers a compelling vision for the future of the web.
For businesses looking to optimize data management, reduce cloud costs, and improve resilience, integrating IPFS with existing infrastructure is a forward-thinking move. And with solutions like Pinata, the transition to a decentralized web is more seamless than ever.
If you’re ready to explore IPFS, Pinata provides the tools to get started. Sign up today and begin leveraging the benefits of decentralized data storage and distribution.