
Back to blog

Announcing the Pinata Vector Storage Public Beta

Today, we’re excited to unveil the public beta release of Pinata’s Vector Storage product. Every customer, on every plan, will have access to this new feature. We welcome all feedback as we move towards general availability.
What is it?
Vector embeddings are a tool that allows developers to perform robust similarity search across disparate data sources.
Specifically, vector embeddings are numerical representations of data that capture the meaning or key characteristics of that data in a multi-dimensional space. Imagine you’re trying to represent a piece of text, an image, or any other type of information in a way that a machine can understand. Instead of dealing with raw data like text strings, embeddings transform that data into a list of numbers (a vector) where similar data points are closer together, and dissimilar ones are farther apart.
For instance:
- A sentence about "puppies" and "dogs" might be represented as vectors that are close together.
- A sentence about a beach and one about a forest might have vectors that are further apart.
This becomes important when a person is searching for something or asking a question, and we need to provide additional context for the search, or need to provide a list of possible answers. Vector search creates a vector of the search/chat query and then compares it against the stored vectors to find the best match.
Pinata’s big innovation here is that we approach vector storage and search as totally connected to the file, whereas other vector storage solutions are wholly disconnected from the file that the vector represents. We call this file-first vector storage.
Because we approach things file-first, we reduce a ton of complexity and latency for developers. In the traditional vector storage and search world, these are the steps if you’re building an AI chat app with augmented prompting:
- Upload source file
- Vectorize source file
- Add metadata to some linking between the vector embedding and the source file
- Take user query, vectorize it, search vector embeddings
- With the vector match, find the linked source file
- Load source file and provide the data from that source file to augment the AI chat prompt
With Pinata, the steps are literally cut in half:
- Upload and vectorize file in tandem
- Take user query, vectorize it, find vector embedding match
- The match (optionally) returns the source file for the best match that can immediately be provided to the AI chat prompt
How does it work?
Pinata’s Vector Storage is a developer tool available via our API and our Typescript SDK. Let’s take a look at how to upload a file and vectorize it using the SDK.
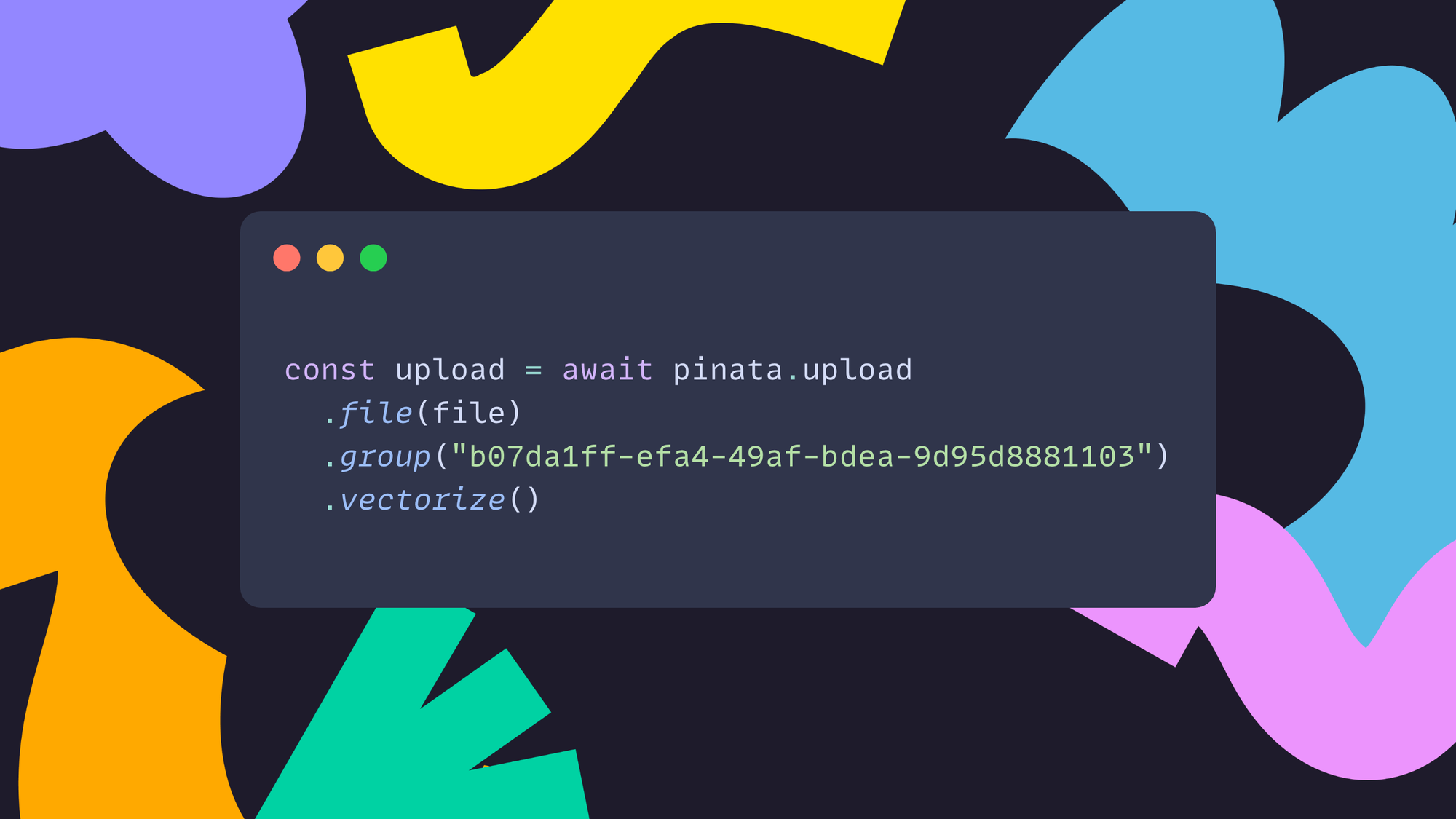
Now, let’s take a look at how we would search vector embeddings and return the file for the top match.
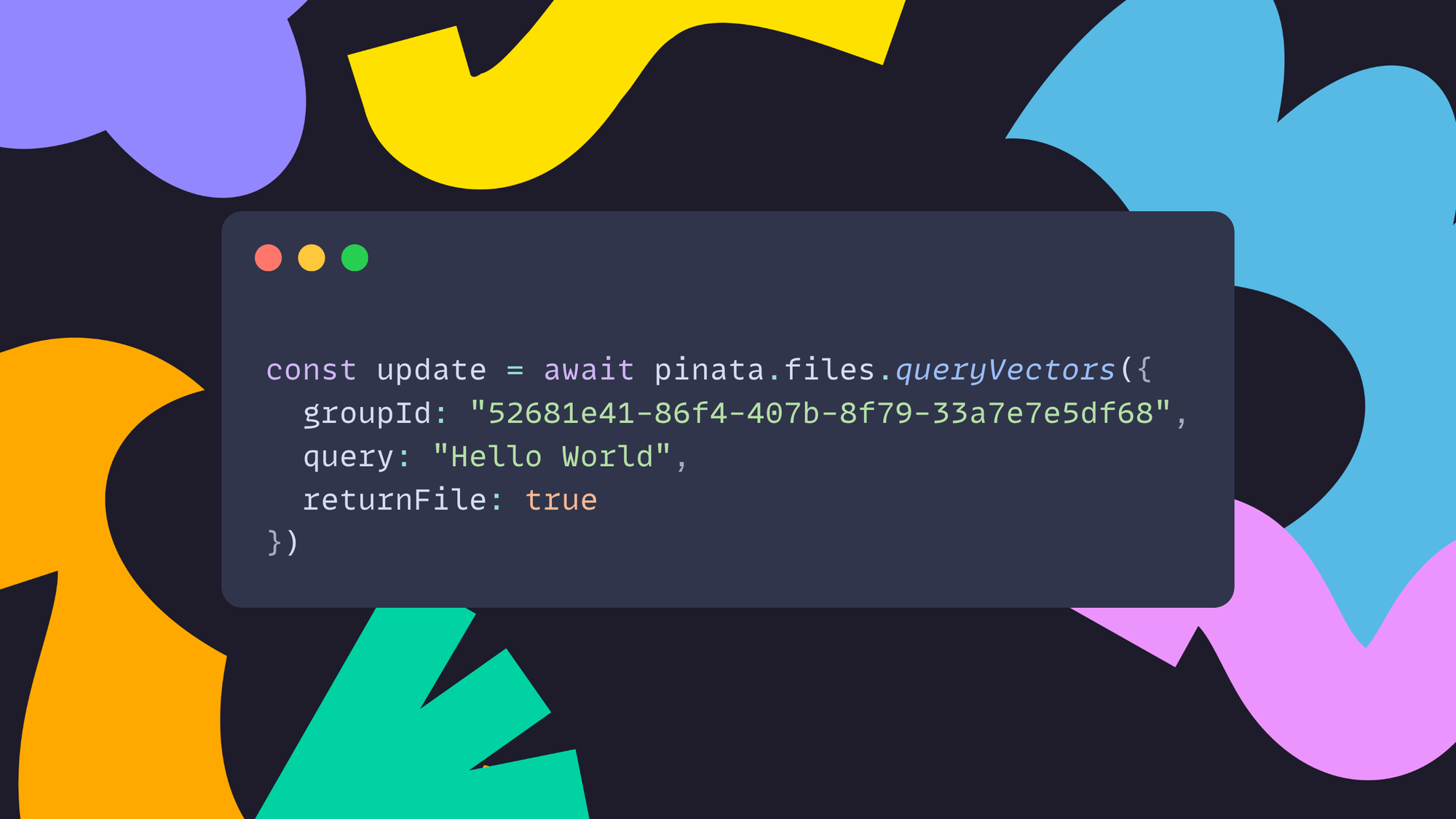
Beyond returning the file for the top match, you can also list matches which is useful in search applications. Learn more about what you can do by reading our docs here.
Limits
Since Pinata Vector Storage is in public beta, there are specific limits you’ll need to be aware of:
- 5 total vector indexes (represented by groups)
- 10,000 total vectorized files
- Only available for private files (not IPFS yet)
As we learn more through the beta, we will increase these limits.
Start now
You can start using Pinata Vector Storage today. Sign up for a free account, or use your existing account. This is a developer-focused tool so be sure to consult the documentation.
Happy vectorizing!